Waiter Duty
Ishan Chatterjee and I produced an autonomous hors d’oeuvres waiter for our final project in Prof. Radhika Nagpal’s Autonomous Robot Systems class, using Turtlebot and ROS. Below, see the video of the robot in action, followed by the republished report, then the source on BitBucket. Enjoy! 🤖
Authors: Nicolas Chavez, Ishan Chatterjee
Course: Harvard CS 189
Instructor: Professor Radhika Nagpal
TFs: Michael Kester, Serena Booth
Goals
The original goal of our robot Triton at the “final project party” was to fulfill the food server role as well as the party photographer role. We had imagined that to do so, it would have to do a couple of things well:
- Approach people at the party
- Offer people food
- Ask people if they want their picture taken
- Take a picture and upload to Twitter
- Recognize when supplies have run out
- Return to base to get refilled
We imagined that Triton would work best at a social gathering with a predetermined “home base” that it would travel to in order to get refilled. Flat, uniform terrain would enable the robot to move and keep reasonable readings from odometry. We also expected that a single rectangular room would be ideal since a more complex layout would necessitate a prior mapping of the room. Indoors would be the ideal case, since our depth sensors for obstacle avoidance would not experience interference. Additionally, any camera calibration we had done with relation to coloring would stay consistent from testing to deployment.
In the end, we ended up reworking the project to exclude the photo taking from the scope in order to focus on the food server aspect of the project. We discuss each part of the goal in greater detail:
1. Approaching people at the party
To successfully approach partygoers, we decided that Triton had to negotiate the bounds of the room and moving obstacles, namely the people themselves. Additionally, we thought that it was also necessary for Triton to be able to cover a large area and explore effectively. We also thought that people detection might work well to approach people from farther away, followed by face detection to engage the person.
2. Offering people food
To do this, Triton would have to recognize faces and then engage them. This required text to speech, or some kind of verbal communication. In the worst case, the person would hear someone talking right by them and turn around, after which the face detection would kick in. Instead of trying to have a long conversation, we thought that Triton could simply offer them food in a one-liner.
3. Asking people for photo
After the person had taken the food, we imagined Triton would again ask them a simple question, one which had a simple answer we could listen for: yes or no. This would have required speech-to-text conversion and then further analysis for an affirmation or a lack thereof.
4. Taking picture and uploading to Twitter
This would have been another extension of the face detection – we thought that Triton could find a weighted “middle” focus area to home the camera on by taking into account all faces detected in the scene. After having taken the picture, we imagined that Triton would post the image to his Twitter feed.
5. Recognizing when supplies have run out
We thought that having highly distinctive markers under each food item on our tray would enable a computer vision solution. When a food item was gone, a visual marker was then made visible. In this way, Triton could count the amount of food items left, with another camera pointing at the tray. It would be initialized with a number during refill, which would tell it how many it started with. Upon reaching 0, it would return home.
6. Returning to base to get refilled
To return to base, Triton would have to either see the base, or “trace its steps”. We figured that a combination of both might work best – odometry could be useful to get close enough to the base to get a clear line of sight, after which we could use visual homing. Upon its arrival to home base, Triton would indicate this and be ready for refilling.
These things together could make for a robot that performed its job robustly and with minimal human reliance.
Implementation
Our final implementation consisted of mostly similar features and flows, with some modifications:
- Approach people at the party
- Scan for faces
- Offer people food
- Recognize when supplies have run out
- Return to base to get refilled
As stated earlier, we ended up reworking the project to exclude the photo taking from the scope in order to focus on the food server aspect of the project. This was done especially because of the unexpected challenge that was returning to base while doing complex tasks such as obstacle avoidance and simple mapping.
1. Approaching people at the party
We started this by implementing a navigation system that traveled to a given robot pose, which was specified by 2d coordinates and an orientation. We then implemented a system on top of that that would segment incoming depth images and decide which direction to travel to, in a step by step manner. This system would convolve the segmentations and determine which directions had gaps of sufficient widths to avoid obstacles. The system would then choose the best direction, out of a set of discrete, pre-chosen mini-routes. When left with ambiguity, the system would choose the direction that minimized the distance to the goal, whatever it was set to be.
We found that in practice this worked very poorly for covering a room since the robot moved very slowly during this step by step movement. Additionally, the field of view of the depth camera did not correspond well to the motion decisions since the angle was small. Furthermore, covering an arbitrary and unknown room would be difficult by just feeding the robot random destination poses, some of which could be inaccessible (e.g.: people in that position, poses beyond walls). Below is an image of the discrete movements and patterns described above.
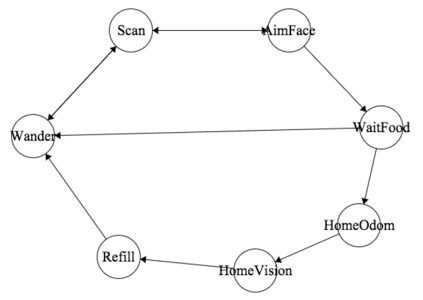
We had noticed that wandering akin to the Roomba, as done in our first assignment, was an effective way to cover a room. With some upgrades to make sure Triton would avoid obstacles and take routes it fit through, this approach made sense for approaching people. This ensured smooth, continuous movements as opposed to more jerky ones. We had also decided to nix the people body detector since the HOG classifier we had tried worked poorly with multiple people in the scene. Additionally, the detector was very slow and inaccurate, making it not much better than just using depth camera obstacle avoidance. This approach involved convolving the depth images as before, in order to determine gaps between obstacles of necessary width. This data was then fed back to modify the angular velocity of the robot to orient it towards the gaps. This was called the “Wander” mode, and it would last for 10 seconds before scanning for people.
Below are two visualizations we used when testing. The images on the left are the color cameras that correspond to the same depth camera. On the depth camera, you can see colored bars at the top of the image, which are longer when that segment of the image is viewed more favorably. After each segment is scored, we chose the group of 3 contiguous segments that give the best scores. We then aim the robot at the center of this group, so it can pass and fit through that space. The blue bar indicates the center of this group, and the pink circle denotes the direction on the image.

The area left of the obstacle (recycling bin) is chosen as the optimal direction

The area to the right of the obstacle (recycling bin) is chosen as the optimal direction
2. Scanning for faces
To engage users in conversation, we used a Haar classifier to perform face detection, which worked at a reasonable speed and success rate. After wandering for a fixed amount of time, we programmed Triton to stop and rotate slowly, looking for faces. Upon encountering a face that was stable for more than another fixed amount of time (to ignore noise), Triton entered a “face aiming” mode, in which it would fix its orientation finely. Once the detected face was within a center threshold of the image, Triton would then start its offer. In this phase, it would transfer from the “Scan” mode, in which it would search for faces, and the “AimFace” mode to home in on a particular one, as needed. Below is an example of the face detection.

The green box highlights the bounds of the face picked up by the Haar classifier
3. Offering people food
To offer people food, we attempted to use the text-to-speech module that was recommended during an earlier lab assignment. Although it was quick to setup, we realized that the voice was hard to understand without knowing before hand what the robot intended to say. This would discourage first time users from interacting with the robot. To mitigate this, we decided to record human voices for the robot to play. Initially, this was also confusing, since a user would turn around looking for a human to talk to, not expecting the robot behind or to the side of them. To get around this problem, we used a recorded voice that sounded more artificial, but vastly more intelligible than the completely synthetic one.
After offering the food, Triton was made to wait a fixed amount of time to let the user select and take a food item from the tray. This was the “WaitFood” state that the system would take on. Once this was done, Triton could then make a decision for its next course of action.
4. Recognizing when supplies have run out
Because we had wanted minimal manual human operation, we decided that we could automate the food refill process by having Triton realize when it had run out of food. To do this, we mounted a second webcam looking down at the tray on the top platform. By counting the visual markers, we could determine the number of spots left, as described earlier. We calibrated our process by using hue values, given that the markers that we chose were a very distinctive shade of green. We would then convolve the image with blur filters to remove high resolution noise, followed by a round of erosion and dilation. Below is an image of the color thresholding we performed in our first step:

The eight square markers were the visual indicators we used
After all markers were visible, Triton would shift to its “HomeOdom” state, in which it would attempt to use odometry to return home. If at least one of them was not yet visible, Triton would return to its “Wander” state in search of other people.
5. Returning to base to get refilled
We found that the method we had initially attempted for wandering – moving in slow discrete steps – would work really well for homing with odometry information. This was because we had implemented a pose-to-pose system that took distance to destination into account. Because these movements were slow and small, we were able to maintain odometric reading integrity, that is, we were able to stay confident about Triton’s position and the base’s position relative to it. When implementing this method, we realized that the robot was reliably off by about a meter or so. To mitigate this, we included visual homing, as described earlier. The combination of these proved to be very effective. Below is an image of the decision making for these discrete steps.

The blue lines indicate the image segmentation and the blue circle indicates the path to go down
To visually detect the home base robustly, we decided on using a tall cylindrical, bright blue object. We chose a tall object so that it could be visible from far away, despite people being in the way. We also chose a cylinder since it would look the same from all directions. Additionally, we would only select objects that had an aspect ratio as small as the very tall object. The bright blue tape was used since not very many things were of that hue. In all, not a single one of these features were enough for the robot to distinguish uniquely and accurately, but it was the combination of these that made the object detection reliable.
The robot would switch to this visual homing mode when its odometry told it that it was less than a meter away from the suspected home position. This is the “HomeVisual” mode. The robot would then run a system similar to the wandering movement, avoiding obstacles while prioritizing a target, if the color camera had identified one. The robot would finally “claim” it was at the base once it had determined the bounding box for the target was large enough and reached from the top to the bottom of the image. Below is an example of the visual homing, which looks similar to the wandering system, since it is based off of it.

The left image, the depth image has bars similar to the wander image, with the ring specifying the optimal orientation. In the color image on the right, the base is demarcated with a rectangle.
Upon claiming it had returned to base, Triton would return to its “Refill” mode until a human operator pressed a button on the numpad to command it to return to “Wander” mode.
Below is a diagram of the state machine that Triton would take on during its role as described above:
Results
When deployed, Triton did not work exactly as expected for a few reasons. Initially, Triton could not get its cameras to cooperate: it was impossible to get all three feeds simultaneously. Eventually, we discovered that the cause was that there was too much of a power draw by the three devices, which led to failure when the laptop was low on battery power.
After solving this, we had to recalibrate the tray camera to recognize the food markers since the lighting conditions were vastly different from the conditions in the lab. After doing so, Triton worked very well, performing its tasks correctly. However, upon correctly determining that it had no more food left, it would fail to get to the base and claim it. It was processing the odometry correctly, yet failed to do visual homing well. We later realized that this was because of the same change in lighting conditions we had not recalibrated for. Later, in the lab we were able to produce a working waiter after accounting for these problems.
The strengths of our system included its success in identifying the number of food items left, its success in visual homing (when correctly calibrated), and its reliance on odometry to return home. These were the most important and most challenging parts of its interaction, which we tried to focus on during development.
The weaknesses of Triton included its obstacle avoidance, which was less robust. Although it would navigate around simple objects easily, many times it would notice too late if it was on a collision course, in which case we built a fail safe that would spin it around until the path was clear. Solving this problem well was something we spent a lot of time on, attempting to use the point cloud library. Eventually we realized that the field of view was too small to take very decisive movements from (hence the small discrete steps) and that properly solving the problem would lead to using gmapping, which was outside the scope of the scenario we had imagined.
Additionally, we encountered a small bug where the robot needed to be given a small nudge each time it returned to the odometry mode.
In all, the robot system turned out to work successfully in the scenarios we had imagined, and all the systems we had described worked well in conjunction with each other.